
Edge computing is a method of processing data locally, close to users and devices. This saves bandwidth and reduces latency, resulting in the high-speed digital experiences people have come to expect.

What is edge computing?
What does edge mean?
The edge works like an ATM. No matter where you are, there is always one close by, so getting cash is quick, easy, and predictable. Processing data close to where users and devices are makes access from any location fast and frustration-free by reducing latency. Latency is that annoying delay you might experience between navigating to a website and waiting for the page load, or that tap on a mobile app and the extended time it takes to complete an action. This usually happens because data processing and storage are physically far away from you. When these processes are moved to the edge, geolocated near you, near real-time digital experiences are possible.
An evolving term, “edge” can refer to an edge server, a user’s computer, or an IoT device. It’s a place where processing and data are spread out away from the core of the data center to bring data and decisions closer to users and devices to deliver better user experiences.
As industry expert Gartner VP analyst Bob Gill described in The Edge Manifesto, the edge is designed “for the placement of content, compute and data center resources on the edge of the network, closer to concentrations of users. This augmentation of the traditional centralized data center model ensures a better user experience demanded by digital business.”
The edge is architected to create nimble, massively distributed installations that provide access to services that help businesses minimize latency, maximize scale, and provide a consistent security posture for apps deployed on any platform. The result is a fast and seamless user experience.
How does edge computing work?
Edge computing is like a doctor’s office with its own lab. Get your exam, lab tests, and results right there, on the spot. With edge computing, your data is collected, analyzed, and processed at the edge, right where people are interacting with you online.
At the most basic level, edge computing brings data, insights, and decision-making closer to the things that act upon them, like an IoT device or a user’s computer. Rather than relying on a central location that can be thousands of miles away, the edge is as near to the “thing” as possible. It’s how the physical and digital world interact at the edge. Edge computing translates those interactions into data, which can be used to make a decision, look for patterns, or pass the data back to a storage or analytics application for further analysis. The goal is ultimately a reliable, scalable implementation so that data, especially real-time data, does not suffer latency issues that can impact the purpose or performance of an application.
Related Content

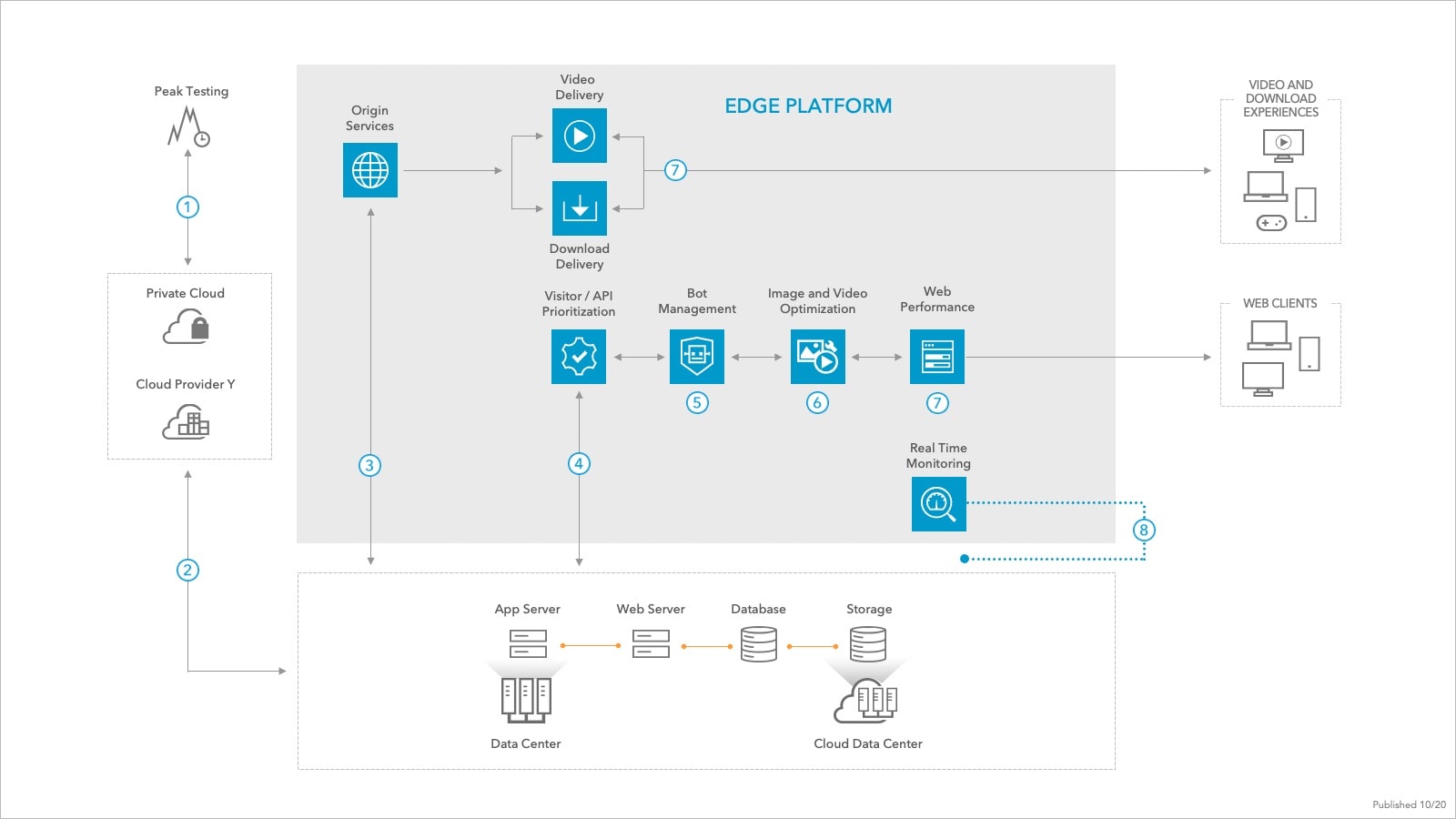

What is edge computing used for?
Edge computing is in use all around us and continues to grow and expand. Consider the daily interactions you may take for granted where you expect the response to be instantaneous. This spans from tapping on mobile apps, buying things online, checking your bank balance, and streaming media — to interacting with a connected device like a light, doorbell, or car — even checking in for a train or flight. All of these services require real-time information processing at massive scale. They are all examples of where edge computing can make the difference between a great experience and a really slow, frustrating one.
Edge computing is not a new idea, but one that for decades was too far ahead of its time to be fully appreciated. High-speed stock market trading or optimizing and localizing services at branch offices are two long-standing examples of pushing business logic closer to where the action is. Modern technology brings more opportunities to leverage the power of edge computing, including enabling faster decisions for connected cars and other IoT devices or improving network processing speeds with 5G.
What are edge servers?
During the 1990s when content delivery networks (CDNs) were first created, edge servers were developed to serve web and video content faster by deploying it in close proximity to users. This was the dawn of the edge computing era, when the first commercial edge compute services that hosted applications like shopping carts and real-time data aggregators were born.
Simply put, edge servers are a type of device that run processing at an edge location as an entry point into a network so that users can access content and resources like web applications with immediacy.
Is a CDN the same as edge computing?
In the expanding definition of what “edge” means, a CDN may be considered a form of edge computing. CDNs are traditionally built from conventional servers to store cached data. However, in today’s world — if you’re already on a CDN and that vendor allows you to write code (to interact with the CDN), that’s CDN edge computing. Edge networks can run on anything from conventional servers to smartphones and IoT devices, and they are able to process and store data.
What is edge vs. cloud?
Cloud computing and edge computing are different technologies. They aren’t interchangeable. While cloud computing is used to process non-time-driven data, edge computing is used to process time-sensitive information.
Beyond being preferred for its latency reduction, edge computing is often chosen for remote locations where connectivity is poor or limited and local storage is required.
What is serverless computing?
Serverless computing is sometimes referred to, or confused with, edge computing. Although there are similarities, edge computing can provide dynamic content assembly, security protections, bot management, and much more to the edge — closer to end users’ devices. This allows businesses to configure and deploy these functions as part of their content delivery.
Also known as function as a service (FaaS), serverless is a zero-management computing environment that allows developers to deploy and execute event-driven logic and contextual data without having to manage and maintain the underlying infrastructure. It is another style of cloud computing where the developer is only concerned about the code being run. The cloud vendor manages how the code is run — and any performance and scalability needs — automatically, so the developer has no need to manage the OS or middleware.
Serverless environments typically exist within centralized compute clouds or edge clouds and offer pricing models based on the resources that applications actually consume.
Core benefits of serverless include eliminating infrastructure maintenance tasks and shifting operational responsibilities to a cloud or edge vendor, and autoscaling to avoid the need to build out extra capacity in advance.
Serverless computing frees up developers so they can focus on key features of the digital experience. Additionally, serverless environments can provide scale, reliability, and cost efficiency, since you only pay for what you use.
Traditionally, serverless environments provided a compute framework with programming language support, a read/write data store, and developer tools that assist in code management, activation, and monitoring.
What is the future of edge computing?
More and more, people and things, as well as systems of both, interact with one another. This presents new opportunities for edge computing solutions to provide value in layers of hardware, software, and code.
According to some industry reports, enterprises may invest close to $250B on edge computing by 2024. Capturing this value demands that the edge be well understood, that edge platforms provide both integrated services and integrations with other ecosystem providers, and that businesses appreciate when latency and digital transformation require centralization versus distribution to capture value.
How is edge computing implemented?
Edge compute can be a complex theme and difficult to grasp. Let’s break it down into two simplified examples where businesses faced challenges with cloud platforms, and cloud computing and edge computing solved the problem.
Accelerating geolocation
Personalization is an important part of a modern user experience. Displaying local inventory and offers is key, yet not always easy to do. Geolocation allowed one popular automobile marketplace to tailor its inventory and information, and share market-value pricing, ratings, reviews, and sales information.
As simple as it sounds, retrieving this data requires many calls to the web application. When a user accesses the app, a geolocation microservice allows the app to filter what it shows. Microservices are a way of developing software applications through independently deployable, modular services. The challenge was that the calls to retrieve up-to-date data add latency. The geolocation microservice made pages load between 500 milliseconds and 2 seconds slower. While that might not seem like a long wait, with the demands of today’s consumers for speed along with busy schedules, it is significant. Shifting the microservice to a solution that injected the geolocation data via a cookie at the edge saved 99% of the round-trip time. This means the microservice now returns geolocation data in 20 milliseconds. For someone looking to buy a car and quickly compare costs and specifications, this time improvement in delivering information was essential.
Global connections
Most people who have flown have experienced the following problem. You know your scheduled flight time. You download the airline app to get notifications. You check flight trackers and the airport website to verify. When you get to the airport, you check flight and gate information on the screens. And once you are at the gate, you look at the updates at the kiosk. More often than not, the information doesn’t match.
Airlines face many challenges when sending and synchronizing critical data. Inconsistent internet and network speeds make real-time data coordination a real issue. Conflicting flight status information confuses passengers and increases demand for customer service resources. More accurate and timely information distribution increases customer satisfaction and decreases costs.
One global airline solved this problem with an edge compute solution. It realized that standard web applications could not overcome the data synchronization challenge; there are too many applications to keep in sync. Also, web applications stay up to date by requesting information on a schedule (or in response to an event). For example, have you ever played with your phone’s email client configurations? There is a setting for pull versus push message delivery. Pull tells the app on your phone to request updates from the mail server. Push tells the mail server to send you information. You configure the timing of the push or pull based on how often you expect to get new mail. The problem with flight information is the number of applications. The mobile app, airport screens, websites, and gate kiosks pull at different intervals. This means flight delays will show up differently to each application.
The airline used an edge compute solution to synchronize global flight information. This delivered three primary benefits:
- Messages are smaller and delivered faster and more reliably
- Information is more secure because it is only sent to known subscribers
- Every device that displays flight information receives it at the same time
The solution provided reliable automated message delivery and notification in real time, keeping the airline’s customers on time with consistent information at every access point.
The business value of edge computing
Many businesses are still trying to understand when, where, and how edge computing might make sense for their specific needs. Choosing edge computing versus cloud computing will come down to cost when both are viable options. There are some forms of compute that don’t make sense at the edge, just as there are edge computing use cases where low-latency requirements prevent centralizing computing in the cloud.
As broadcasters shift to digital, they need to understand subscriber preferences to design programming and ensure flawless viewing experiences. Designing programming is only really possible with data at rest (data that is not actively moving from device to device or network to network and is stored on a hard drive, flash drive, or laptop, or archived in another way). Data must be collected from a global base, then stored and processed to determine what content to create and how to produce it given the demographics of the subscriber base. Conversely, providing those subscribers with fast startup times and error-free viewing, in their local area, on the device they use, over their specific network connection, requires real-time monitoring, processing, and actions. Value in programming is measured in months and years, but in terms of viewer experience, value is created or lost in milliseconds.
Similarly, it’s important for retailers to understand customer preferences for omnichannel shopping experiences over thousands of interactions to design storefronts and offers that convert customers and maximize their lifetime value. These decisions can’t be made based on individual actions or in real time. This data is also only available at rest, through creating shopper cohorts and personas where merchandise can be presented and promoted to drive purchasing decisions. Assembling that information and adapting it — based on whether the shopper is in a store or online, which device they are using, and how the ecommerce application is behaving in the moment — requires real-time computing to maximize conversions.
Understanding when and where data is valuable is critical. Businesses must assess where the cloud and the edge provide unique value, and then architect their infrastructure and applications appropriately to capture it. Data that maintains its value at rest will be prohibitively expensive to manage and secure at the edge because doing so will create redundancies that the centralized cloud is designed to overcome. Real-time hyperlocal data sent back to the cloud from the edge will fail to capture value while running up costs, because round trips can add latency and errors that result in poor user experiences.
Said simply, if action needs to be taken based on data that is changing in real time, start with edge computing. If data can or must be aggregated, processed, and analyzed to be able to provide value, start with cloud computing.
Learn about Akamai’s industry-leading edge compute solutions
The Akamai edge compute platform helps to build and run applications and services elastically with unparalleled scale, reliability, and security.
For over two decades, Akamai has helped businesses develop edge computing solutions tailored to their specific growth and development needs. With the world’s largest and most sophisticated edge platform, over 4,200 locations and 1,400+ networks in 135 countries — we’re poised to deliver the best in serverless computing, edge apps, and cloud optimization.
Innovation on the edge
With EdgeWorkers, what you can imagine is what you can build. We’ve engineered EdgeWorkers to allow development teams to freely build logic that impacts customer experiences — from traffic routing to dynamic content assembly and beyond — within their existing toolsets and workflows.
EdgeWorkers and EdgeKV enable developers to create and deploy microservices across more than a quarter of a million edge servers deployed around the globe. When development teams activate code at the edge, they push data, insights, and logic closer to their end users. Akamai’s performant and scalable implementation model ensures that data and computation are not hampered by latency issues that can have a negative impact on digital experiences